


As businesses become more data-driven, everything they do results in ever-expanding volumes of data captured, processed, and analyzed. Today, companies generate more data from their systems, share data with business partners, and leverage third-party data sources to enrich their data libraries. Processing ("ETL") this data deluge can paralyze a business or produce a treasure trove of insights. This blog post will explore how organizations meet the scalability and performance analytics demands with growing data volumes and business demands.
The Data Challenge
Data is often called the "new oil" because of its immense potential. British mathematician and entrepreneur Clive Humby coined this phrase in 2006 and widely parroted since. They are similar since both oil and data increase with refinement. However, refining data has gotten more complicated as the volume of available data has increased. In 2023, the amount of data generated will be almost three times greater compared to 2019. We will generate 120 zettabytes of data in 2023, roughly equivalent to 15.7K Webster dictionaries for every man, woman, and child globally. In 2024, we will generate 147 zettabytes of data. We will create more than 181 zettabytes of data in 2025. As data volumes grow, so do the complexities associated with extract, transform, and load processing and deriving meaningful insights. Traditional methods and tools struggle to keep up, leading to bottlenecks, delays, and missed opportunities.
Scalability is a critical factor when handling large volumes of data. Scalable solutions can adapt and expand to accommodate increasing data sizes without compromising performance. Scalability is essential for organizations looking to future-proof their analytics capabilities.
Performance is equally vital. Analyzing data quickly and efficiently allows organizations to make real-time informed decisions. Slow or inefficient processes can result in lost opportunities and decreased competitiveness.
Solutions for Scalability and Performance Analytics
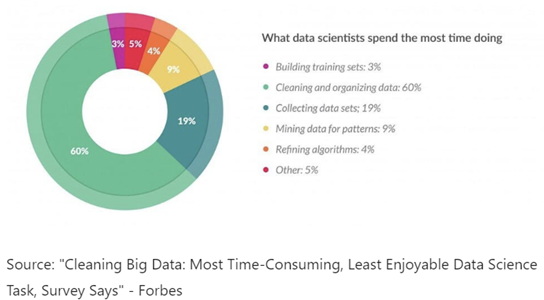
It is widely accepted that analysts and data scientists spend about 80% of their time collecting, cleaning, and organizing data ("data preparation"). Businesses want their analysts to spend more time mining data and implementing the insights found. Lydonia Technologies has developed a set of best practices to create high-performance data preparation operations that I will summarize in this blog post.
Hyperautomation: We believe you should automate everything in the data process that is automatable. Hyperautomation reduces process delays and errors while improving observability and predictability, enhancing the performance and scalability of your operation.
Extensibility: Analysts access data from a variety of sources, including SAAS applications (SFDC, SAP, Oracle ERP), databases (SQLServer, Oracle, Snowflake), and files (Excel, Logs, Access). On average, our customers typically have 12-15 unique data sources. We have partnered with Alteryx, which comes with 60+ pre-built applications and database connectors and 30+ file connectors. The wide variety of supported connectors and easy call-out to Python programs allow quick automation of ETL processes, resulting in easy scalability.
Accessible: Maximizing no-code tools enables the rapid integration of new data sources while minimizing the cost of updating existing data ETL processes with the inevitable changes. By 2025, Gartner projects that 70% of new applications will use low-code functionality or no-code technology. Why? Because we recognize the need for collaboration, low-code apps empower workers with functional domain knowledge to realize the benefits of data analytics.
In Database Processing:
Data movement ("egress") can be expensive and slow. In fact, for many organizations, egress costs are one of the most significant operational expenses across their entire data and analytics stack. Pushdown processing performs the data ETL process inside the cloud data warehouse, removing the need to egress already loaded data while unlocking the nearly infinite scalability of processing resources. We do all this automatically with a tool like Alteryx without any code, special tools, or extra steps. We connect the Alteryx Analytics Cloud Platform to a database that supports pushdown processing and select that database as the processing engine. Alteryx will take care of the rest. Alteryx Pushdown processing is available with all the cloud database engines (Snowflake, Databricks, Google BigQuery, Amazon Redshift, Azure Synapse) and traditional databases (Oracle DB, PostgreSQL, MS SQL Server). In-database processing significantly improves ETL performance by eliminating data latency and delays caused by network congestion, reducing costs.
Conclusion
In an era of ever-expanding data volumes, organizations must have the tools and strategies to meet the demands of scalability and performance to maximize the value of their data. Lydonia has built solutions that allow our customers to turn their data deluge into actionable insights at any scale. Alteryx, with its user-friendly interface, automation capabilities, in-database processing, and scalable deployment options, is a powerful tool for tackling the data challenge head-on. For example, Nielsen faced these challenges and needed to replace their next-day reporting system for audience measurement. They were looking to improve the performance of their existing data and report processing. They also needed to scale by empowering each organization to analyze their data and solve questions and challenges rapidly. Nielsen reduced daily reporting from 4-hours to four minutes. More than 250 analysts are now generating thousands of analyses for thousands of their business users. Review their complete case study to learn more about their journey and results.
Are you ready to unlock the potential of your growing data volumes? Explore the possibilities with Alteryx and embark on a journey to transform data into actionable intelligence. Visit lydoniatech.com to learn more and get started on your data analytics transformation today.